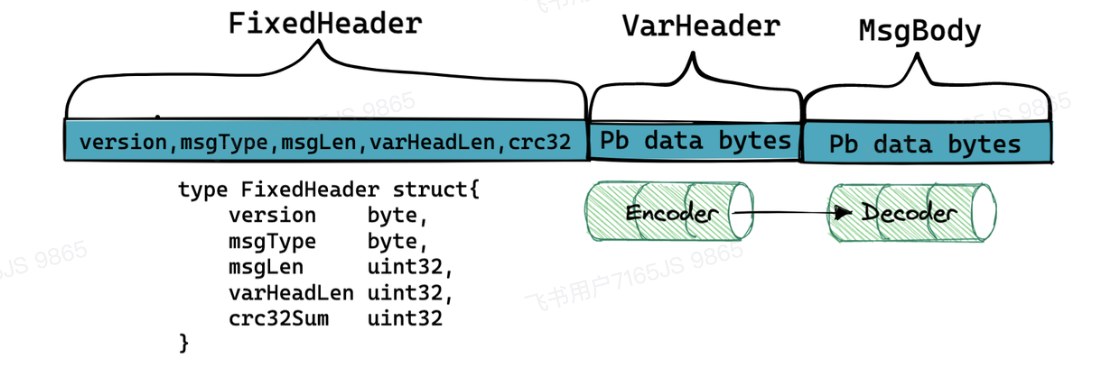
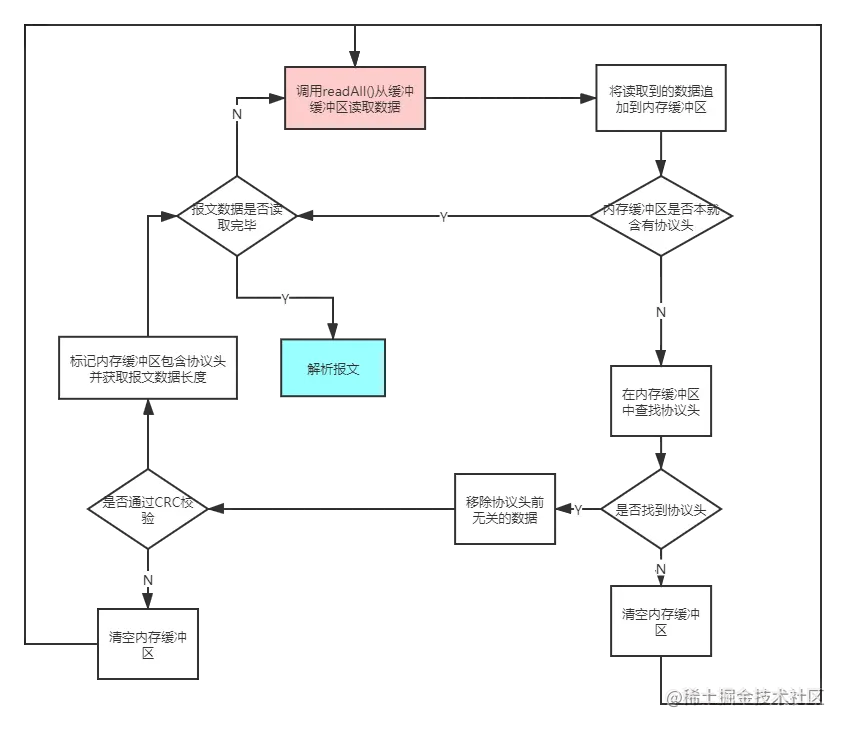
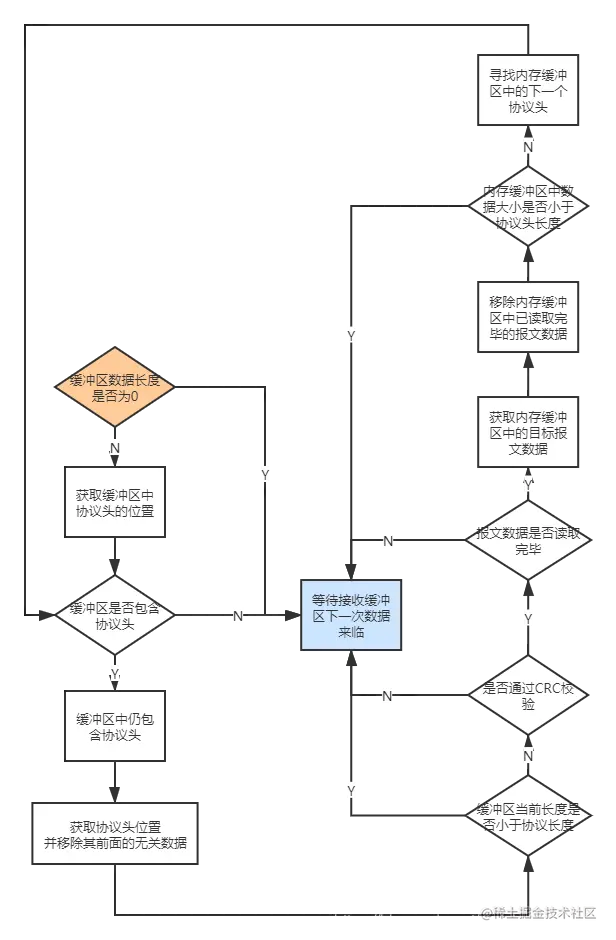
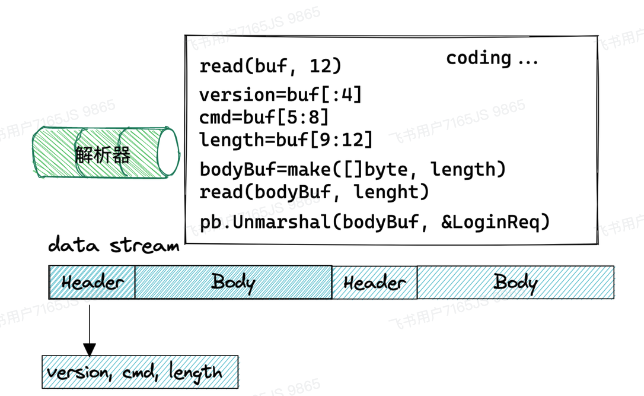
长连接网关设计文档
背景介绍
Plato 为保证消息的及时性需要使用 tcp 长连接与客户端进行通信(节省 DNS, 握手等开销,并可主主动 push 消息给客户端)。长连接服务器需要一直维护连接状态。连接状态通常分为系统部分和应用部分:
- 系统部分指的是 socket 的管理
- 应用部分指的是连接过程中的 uid/did/fd 之前的映射关系,以及 clientID 等信息的存储
这些信息的生命周期是跟随一个长连接的创建而产生,长连接的断开而消亡。持久化除了用于数据分析,同时这些信息也是收发消息维度的访问频率,QPS 极高,因此需要存储在内存中被使用。
基本流程
当客户端初始化建立长连接时
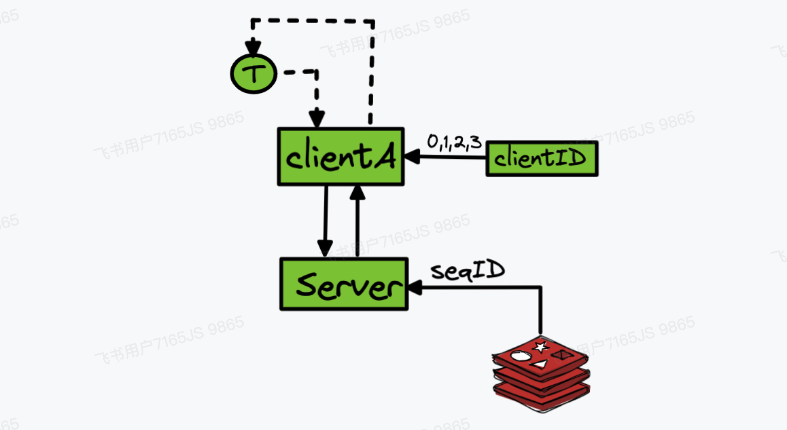
- 向某个 IP 的长连接服务发送创建连接信令
- 网关 server 解析信令得知其为创建连接信令
- 网关 server 获得底层 socket 的 FD,以及用户的 uid/did,建立注册表
- 回复客户端连接建立成功
当客户端发送消息时
- 客户端发送上行消息信令
- 网关服务接收到消息,并解析信令为上行消息信令
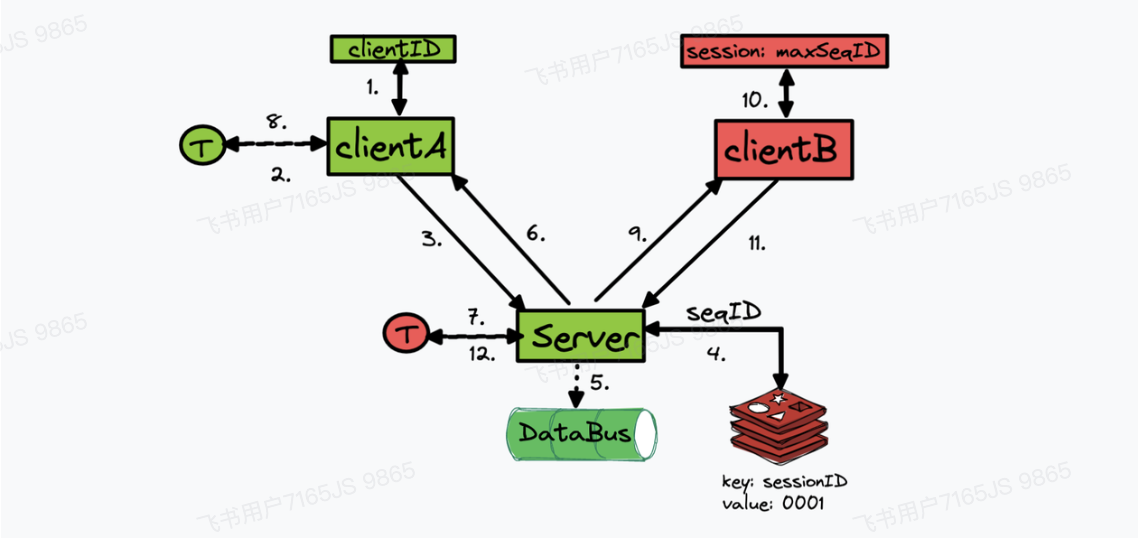
- 根据 clientID 和 sessionID 进行路由,分配 seqID 等状态更新逻辑
- 然后转发给业务层服务处理,确认业务层收到消息后立即回复客户端 ACK
当业务处理后,将消息转发给接收客户端时
- 业务根据 sessionID 定位到该会话的接收者的连接在哪一个网关服务上
- 然后将消息通过 RPC 交给网关服务,网关拿到数据后通过 uid 对应 connID,确定 fd
- 然后根据 fd 找到对应的 socket,将消息拼接固定消息头发送给接收方客户端
当连接断开时
- 心跳超时,连接断开/异常断开
- 状态回收释放
需要的信令
- CreateConn 创建连接
- 发送上行消息
- 发送下行消息
- 上行 ACK 回复消息
- 下行 ACK 确认消息
需要的 RPC:
6. 消息路由
设计目标和技术挑战
长连接接入层主要解决的问题就是实现服务端主动及时地将消息发送给客户端的功能。而在这个过程中,会有非常多的技术挑战:
- 客户端如何选择网关 IP 地址才能降低延迟,保证连接可靠,负载均衡?
- 网关服务如何接收客户端的消息,获得最大的并发度获得消息的高吞吐,低延迟?
- 为了能使用长连接收发消息,需要维护哪些状态,如何使其占用更少的内存,单机承载更多的连接?
- 业务层是怎么感知到连接在哪一个网关机器,并把消息分发下去的呢?如何降低网络请求的局中?
- 客户端进入地铁切换基站/连接 wifi 等情况导致连接断开,如何能快速重连,而不影响用户体验?
- 如何尽可能的减少长连接服务的崩溃/重启次数,做到永不宕机?
- 长连接服务如何做限流/熔断/降级策略?实现对网关的过载保护,提高可靠性?
- 长连接服务如何做到通用性,灵活对接各种业务场景?
- 如何多数据中心部署长连接网关?
评估标准
- 【可靠性】永不宕机,快速重连,快速重启,水平扩展,负载均衡(内存 cpu/网络稳定)
- 【低延迟】收发消息在接入层的耗时 p99 不能超过 5ms。
- 【高吞吐】单机持有长连接数量以及活跃连接每秒收发消息数。
- 【上线频率】指长连接网关在一周时间内开发需求&bug fix导致上线的频率。
- 【可扩展性】不影响用户的情况下增加网关机器或接入其他信令或业务,跨数据中心部署
方案选型
客户端如何选择网关IP地址?
方案一: 写死 ip 列表
- 实现简单
- 代价:需无废死性,更新扩展需要发版
使用 httpDNS 服务
- 优势:
- 可以水平扩展长连接网关
- 精准调度
- 防止劫持
- 实时解析
- 代价:
- 不能针对长连接来做精准调度
- httpDNS 本身也会带来可用性问题
自建一个 http server 作为 ip config server
- 通过一个域名+https协议访问 ipconfig 服务
- 从中获得一批ip列表(减少请求&负载均衡&快速重连)
- 客户端通过ip列表直接tcp连接长连接网关
httpDNS + ip config
- httpDNS 解析获得正确的 http server 的公网 ip 地址
- 然后通过此 ip 地址访问 ip config server 获得 ip 列表
长连接网关设计方案
1. 基于Channel空间的实现方案 (goim)
方案描述
- 一个线程监听accept
- N个accept socket返回后建立连接消息
- 服务端验证会话成功后建立会话消息
- 每发送一个消息启动一个时间对象对应答
收益
- 实现简单,开发快速
- 基于GO的协程机制,可以快速上线
代价
- 内存占用率高,每个客户端都要有一个4G等大内存
- 资源占用多导致负载很高,服务器资源浪费严重
- 一个协程占用4k内存,万方长连接时会占用8G内存
- 每个下行消息都会启动一个定时器任务,将会push很多定时器OOM
2. 单Reactor + 单Select处理
方案描述
- 一个conn对象组建后,分配一个专用客户端conn/Read和send所在channel工
- 在一个select循环上监听所有channel,请有消息到来会立即处理
- 业务回调时,开启一个协程进行注册返回send channel交给业务处理
收益
- 节省了一个协程开销,内存占用减少到三分之一
- 协程数量少于10个,runtime调度开销降低
- 延迟很低,去掉所有定时器和锁的管理
代价
- 同一个机器上响应延迟,需要等待被筛选
- 协程回调会做简单同步
- 外层没有解决下行消息定时器和锁内存的问题
3. Goroutine Pool方案
方案描述
- 一个程序函数监听socket的read动作
- 有信号到达后继续标识
- 业务层回调时,也需要goroutine pool限定一个用来处理socket send消息
收益
- 业务层回调函数化,使用协程池技术,减少了协程调度的开销
- 限制了协程的数量上限,最大减少内存分配
代价
- 还是有一个协程队列
- 需要照顾好conn的引用,引数认为从中获取的协程修改socket
- 还是重工
4. React池 + Goroutine Pool
特点
- 通过epoll系统调用,带收发消息无需事件序列化
- 收发消息无需特别程度
- 当业务层回调时间时,真的从goroutine池中取一个goroutine来处理
收益
- 收发清空完全无阻塞,减少了内存占用
5. 状态连接数表
方案描述
- 创建connect时储存注册相关信息,比如connID等
- 将多个socket连接对应到相同endpoint节点
- 中心化存储sessionID等,uid/did,业务层连接信息
- 映射sessionID到connID的MAP,以及connID到connect对应的Map
- 业务层需要发送下行消息时,可以通过sessionID找到uid,再通过uid找到connect
收益
- 点到点连接可控
- 状态可恢复
代价
- 与持久化相关的高内存,成为难题
- 空间占用相对较高
- session集中化存储时,需要进行约定提纯逻辑
后续内容包括了state server、分布式系统等更高级设计,我可以继续整理如果需要。